NTT、LLM学習データ漏えいリスク低減と応答精度向上を両立する新技術、医療などで活用
掲載日:

NTTは7月7日、LLM(大規模言語モデル)の応答精度を維持しながら、学習データからの情報漏えいリスクを抑える新技術「PTA(Plausible Token Amplification)」を開発したと発表した。個人情報の秘匿性の高さが求められる医療をなどの分野で安全にLLMを利用できるようになるという。
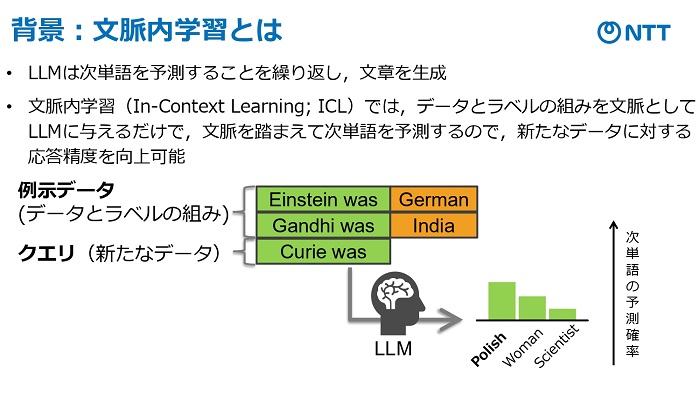
「文脈内学習(ICL)」と呼ぶ手法を使って実現した。LLMは、次に登場する単語を予測することを繰り返し、文章を生成する技術。オープンAIの「Chat(チャット)GPT」やグーグルの「Gemini(ジェミニ)」などの対話型AIで利用されている。
「ICL」は、LLMで「データ」と「ラベル」を組み合わせてプロンプト(指示文)として与えることで、それまでの文脈を踏まえ、次の単語を予測する技術で、データの応答精度を向上できる。
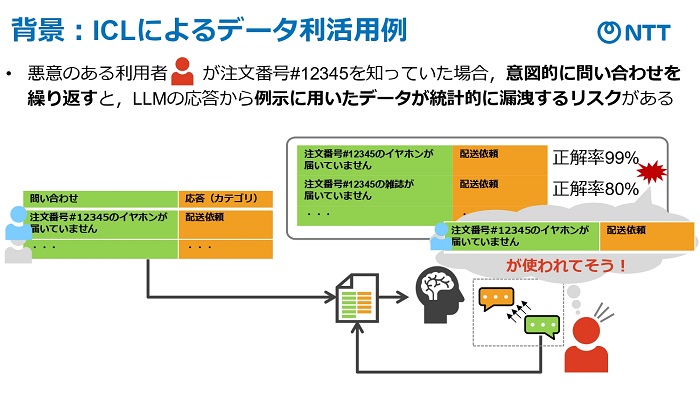
ただ、「ICL」は応答制度が改善する一方で、学習データからの情報が漏えいリスクがある。NTTによると、例えば、LLMを利用したECの問い合わせ応答の場合、悪意のある利用者が注文番号などを知っていると、意図的に問い合わせ内容を繰り返すことで、誰が何を買ったかという情報を推定できてしまうという。
この課題を解決する手法の1つで、元のデータにノイズを加えることでプライバシーを保護する「差分プライバシー(DP)」の技術を利用し、ラベルにノイズを加える「DP-ICL」と呼ばれる手法が注目されている。しかし、DP-ICLは安全性を担保できる一方、ラベルにノイズを加えたことで予測精度が低くなるというデメリットがあった。
NTTでは、DP-ICLの応答精度低下の要因が、ICLがルール(応答傾向)を推定する精度が、ノイズによって重要な単語が曖昧になることで低下すると解明。そこで、事前にルール推定に重要な単語を強調し、ノイズを加えても明確にすることで応答精度の低下を解消する技術「PTA」を開発した。
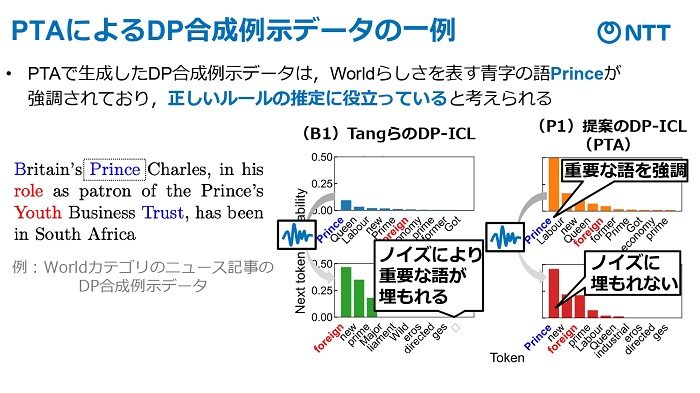
「PTA」で、ニュース記事をスポーツや世界情勢といったトピックのカテゴリに分類するタスクでの実験では、精度がDP-ICLよりも高く、ノイズを加えないICLと同等であることを確認できたという。
今後は、生成時の単語の強調処理を高度化し精度の向上と、柔軟な構造の入力を扱うタスクへの応用も視野に入れ、データのセキュリティーに配慮したLLMの活用環境の実現を目指すとしている。




